We are successfully using extremely complex technology every day without understanding it. An examples is our smartphone, which has become a powerful computer in recent years. This approach is successful whenever we are allowed to treat technology as a black box. In this case, we don’t care about the internal machinery of a device, but just about how it generates output from input:
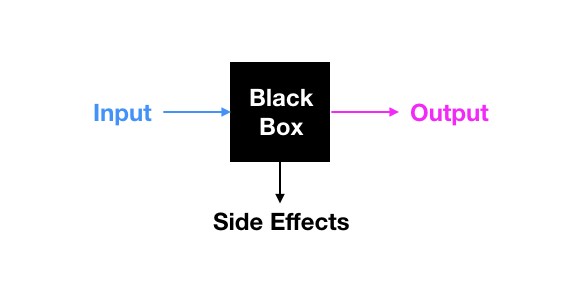
To make the black box treatment of a technology work well, the following conditions need to be satisfied:
- The input is clearly defined and easy to understand
- The output is clearly defined and easy to understand
- The transformation from input to output is clearly defined and easy to understand
- The transformation is more or less ideal („always works well“)
- The transformation has no significant side effects
Another example where black box treatment works, is the audio amplifier of our stereo system. It takes a small audio signal (like from a microphone) as the input and amplifies it for the speakers (output). Input and output are obviously easy to understand, the transformation (amplification) is also clearly defined and easy to understand. Modern amplifier’s distortions are almost not audible anymore and we can also ignore heat production and energy consumption. Therefore there is really no need to understand how an amplifier works internally. It can be used by laymen with great success.
Unfortunately most advanced Data Mining methods don’t satisfy all of these conditions:
- Input not easy to define / understand: The input to a data mining algorithm is data. And the quality of the output depends on the data properties such as the features selected and distributions. E.g. how valid is the output if the data is heavily skewed?
- Output not easy to define / understand: Clustering algorithms are used to find clusters in data (e.g. for customer segmentation). But what is a cluster? The answer to this questions is not so easy. You might want to choose a centroid based or a density based algorithm. Which is better? Many clustering algorithms also find clusters even if there is no cluster structure in the data. Without some knowledge what clustering algorithms really do, it is nearly impossible to interpret the output correctly.
- Transformation not easy to understand: Dimension reduction algorithms like t-SNE produce impressive visualizations. But what is the algorithm really trying to do? Again, without some knowledge it is very easy to misinterpret data. Also the result of many algorithms depend on the value of hyperparameters, which are not easy to understand.
- Transformation not ideal: The output of a clustering algorithm might depend on initial randomization. If you run the algorithm on the same data several times you might get different results. Results might be just approximations which yield poor results with some data.
- Significant side effects: Some algorithms might take a (too) long time to compute the results for large data sets.
Of course all this can (and must) be explained to the management by a well communicating data scientist. But the lack of related knowledge in the management nonetheless is a huge bottleneck for the adoption of modern data mining techniques. Most companies are still using only simple bar and pie charts by category to analyze their data. This might be still better than using advanced methods without understanding them. But Data Mining is too powerful to be ignored forever.
Disclaimer: we offer various tech courses (including Data Mining) for managers in Switzerland: https://hop-on.tech
Title image: Shutterstock / Dragance137
Illustration © author